
AI Paradox – From Pilots To Mainstream
By Avantika Sharma, Brillio

Organizations have been moving from individual AI pilots to commercial applications of Deep Learning to serve a large customer base. Our typical IT systems fundamentally have a data input, tool and output while AI systems learn algorithms with training data which makes it more difficult when AI systems scale and start interacting with multiple systems. Machine learning data management, model building, training and validation, optimization and deployment, are all positioned to become a real-time operation. On the other hand, there is a huge demand for edge compute processing while sending some data to a centralized system in order to build more intelligent machine learning models and gain further insight.
In the past few years, we have seen that various dimensions of AI like Machine Learning, Deep Learning, NLP, Computer Vision, Neural Network have evolved disproportionally. With large datasets, inexpensive on-demand compute resources, accelerators on various cloud platforms, we have seen rapid advancements in a) Research, b) Frameworks however we have been relatively slower on c) Application architectures and c) Deployment and Infrastructure leading to AI adoption in mainstream environments. In order to facilitate faster adoption at scale into real-life application architectures we need to apply the frameworks, research, and infrastructure at a faster pace.
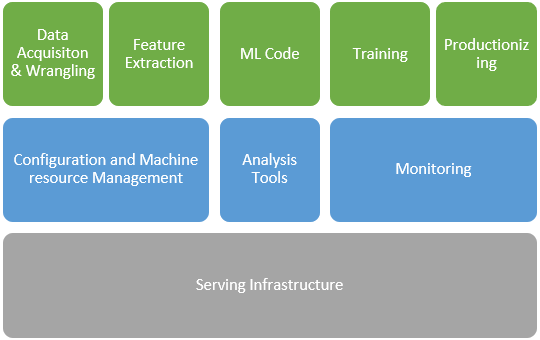
Machine learning specific life cycle management frameworks addressing Data Acquisitions, Feature Extraction, Model Training and Productionizing for mainstream environments at scale have particularly seen a rise in the past couple of years.
Many of the technology companies have made their AI scaling frameworks available which are now seeing adoption by various industries like:
- DAWN by Stanford,
- Michelangelo by Uber,
- DataBricks ML flow,
- Netflix Metaflow,
- Facebook’s FBLearner flow and
- Google TFX
These frameworks combine mainstream technologies with proprietary ML technologies like PyML, Pyro, PyTorch, Tensorflow, etc. which makes it easier to scale AI on real like application architectures.
AI deployment at scale and Infrastructure also has seen immense progress in recent years from cloud providers like AWS, Azure or GCP. We can spin up customized environments, containerize applications using docker, and scale horizontally instantly while providing SLA and uptime.
Despite of the progress that has been made in the available frameworks and the Deployment capabilities AI Scaling Challenges continue to be multifold, therefore identifying and using the right Scaling Framework for the enterprise can help debottleneck many of the below issues.
- Heterogeneity
AI applications are often written in different languages – Python, R or Scala based on the business use case. Even within the language, there are various frameworks and toolkits like TensorFlow, Pytorch, Scikit, etc. which a data scientist depending on the needs. Apart from the model development one of the most important aspects of ML applications is Data pre-processing and the most preferred JVM based system for the same is Apache Spark as it provides better support of parallel executions. It is common in almost all enterprise use cases and applications to have above heterogenous codebases which makes it difficult to maintain. Having the right AI Lifecycle Management tool can help track and log the dependencies automatically during model training phase which can then be bundled up along with the model for production deployment.
- AI Applications Don’t Exist In A Vacuum
AI deployments are not self-contained and have to be embedded or integrated with applications. Most of the enterprises have moved/are moving to Microservices and Mesh-based architecture therefore AI model deployment is being enabled through API layers in a language-agnostic way. In some cases there may be a need for efficient network usage and better performance, example large datasets of images or spike in the demand by end customer during the day may vary or with the advent of 5G, edge device compute (Mobile, IoT) is on the rise. Hence the need for a model needs to be optimized for CPU and memory storage and using the right autoscaling framework.
- ML Ops – Managing Continuous Delivery And Pipeline Automation
Machine learning is composable as its building blocks are more granular and disparate. In real-world applications, ML models are deployed and managed as a single unit or as multiple components each managed and updated individually, for example, a Call Center Automation initiative might require a model to scan all notes taken by the reps, convert the audio from speech to text, translate non-English to English and prepare the text for NLP.
Release strategy and deployment infrastructure for ML must consider the heterogeneity factor and the fact that a Model may include multiple components each built using a different programming language or framework. Each of these components may need to be updated or rolled back independently or as a single unit.
Implementing ML in a production environment is not only deploying the model as an API for prediction but also deploying an ML pipeline that can automate the retraining and deployment of new models to cope up with the business demand and newer data sets. Ensuring a CI/CD process enables to automatically test and deploy new pipeline implementations.
CI/CD And Automated ML Pipeline
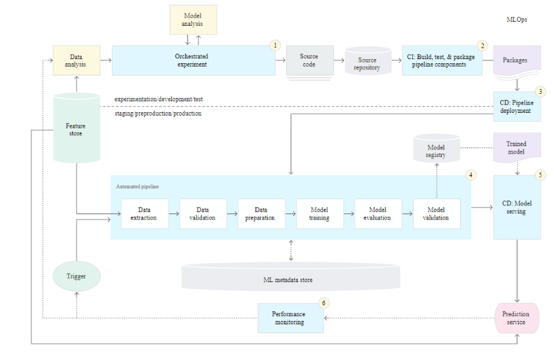
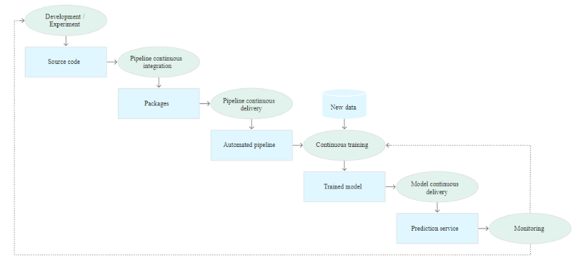
Source: Google Cloud Solutions
- AI Monitoring
To support the cloud-native distributed containerized applications, monitoring tools are constantly evolving to include logs, traces, and metrics. The tools, however, still need to evolve further to support machine learning. The metrics to monitor, the information to log, the compliance needs, and the audit requirements for machine learning are very different from regular applications.
Monitoring should consider the heterogeneity of different languages and frameworks and while microservices architecture with containers, service meshes and immutable infrastructure are great techniques to deal with this, these tools are not easy to configure and maintain. Hence a focused approach is needed for the same.
ML specific metrics that require a focused framework to be monitored are:
- Data Drift: drift computation of a) training & actual feedback disparity (output), b) drift computation of training/runtime data disparity (input) and c) drift computation of correlation across features
- Accuracy: how good are the model predictions, based on feedback and actuals received
- Bias: computation of Input vs. Output (train vs. actual)
- Anomaly: detection and logging all inputs with anomalies
Docker/Kubernetes and micro-services architecture can be employed to solve the heterogeneity and infrastructure challenges. Comet and MLflow are trying to address experiment versioning and reproducibility problems. Cloud platform services such as SageMaker, Azure ML, Google AI cater to the scalable deployments. Existing tools can partly solve some problems individually. Bringing all these tools together to operationalize AI is the biggest challenge today which can be resolved by using the right framework and approach to solve the AI scaling problem.
About The Author
Avantika Sharma is Global Head of Customer Success Strategy and Transformation at Brillio.
Strategic senior executive with experience in Digital Consulting, Product Strategy, driving Automation and AI Strategy Development & Execution. Focused on Innovating, crafting Digital Strategy Roadmaps and building Solutions for our customers to drive newer business models and revenue streams with an elevated end consumer experience.